Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
. ), cov( ss yx r ⋅ =
Opisy stanowisk pracowników biura LGD
Regresní analýza
IUVENES URBI (Mladí městu)
Statistické metody_3.pdf
Metódy výpočtu konfidenčných intervalov pre referenčnú hodnotu v
Výběr zaměstnanců IV
Ročník 23, číslo 3, září 2012 - Česká statistická společnost
∑ ∑ ∑2
formát 01/2015
Některé přímočaré početní úlohy
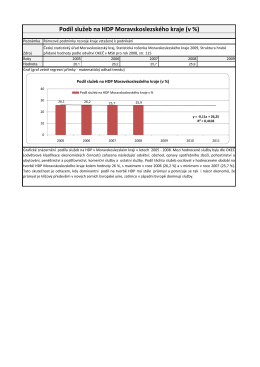
Podíl služeb na HDP Moravskoslezského kraje (v %)
4ST201 STATISTIKA 2. cvičení 4.8.2013