Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
∑ ∑ ∑2
Základy pravdepodobnosti a matematickej štatistiky
Systém hodnocení pracovišť matematické sekce podle výkonů
Przewodnik po pakiecie R
perspektivní komunikace 21. století - SŠIEŘ
Měření přijímací cesty transvertoru TR144H+40
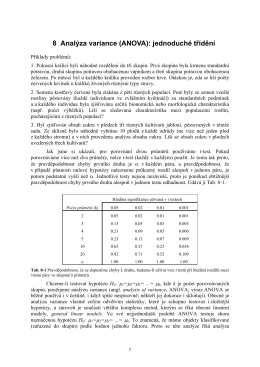
8 Analýza variance (ANOVA): jednoduché třídění
Slovo úvodem Proměnné a konstanty
Prof. MU Dr. Aleš Rejthar, CSc. (1938– 2015)
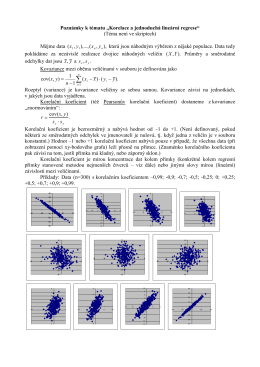
. ), cov( ss yx r ⋅ =
Package `PBImisc`
Başlarken - Prof.Dr. Ünal H. Özden
1 Základní statistické pojmy, charakteristiky souboru