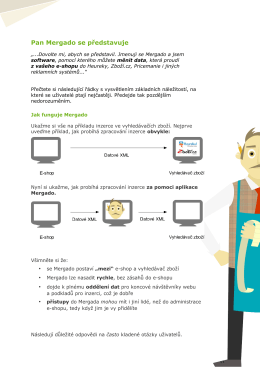
Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
1 Základní statistické pojmy, charakteristiky souboru
V. Lepidopterologické kolokvium 2010
Časté otázky
Základy statistiky
Statistické metody_3.pdf
VCI – moderní oChrana Výrobků před korozí
39. hodina – Savci - vývojově nejpokročilejší skupina obratlovců
Řícmanský zpravodaj č.1 - 2014
14 Vicha.pdf
คุณภาพน้ำทะเลบริเวณปากแม่น้ำบางปะกง พ.ศ. 2545
7. června 2013, Geum 2013
12 Závislost dvou kvantitativních proměnných: regrese
Návod: Sony Vegas