Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Statistické metody_3.pdf
Opisy stanowisk pracowników biura LGD
Kvantitativní metody B
VLKOSTNÍ REŽIM V PLOCHÝCH STŘECHÁCH
vliv kotvení parotěsné vrstvy na její vlastnosti
Ukázky jak prezentovat tabulky a interpretovat vztahy
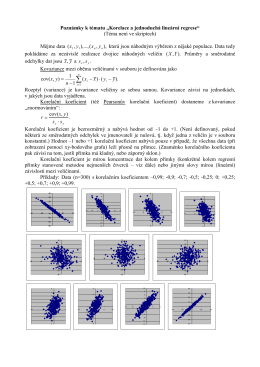
. ), cov( ss yx r ⋅ =
kontingenční tabulky v excelu aneb jak vytřískat z dat co
Srovnávací test Mitsubishi ASX 1.6 MIVEC LPG vs. Subaru Legacy
BLUETOOTH - Sony Europe
1 Základní statistické pojmy, charakteristiky souboru
4ST201 STATISTIKA 2. cvičení 4.8.2013
I Výběrová kovariance a výběrový korelační koeficient II Ilustrační
Vybrané testy neparametrických hypotéz
Věda a umění – dvě tváře kultury
Ukázka zkouškové písemky
ZDE
Model reoxidace
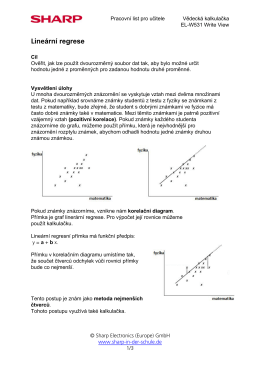
PN2: Statistické výpočty, lineární regrese
Abstrakty časopisu B&IT 2/2014 v českém jazyce najdete zde
Základy jazyka C
A – Technická zpráva
extrakt ISO TR 14813-4