Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
4ST201 STATISTIKA 2. cvičení 4.8.2013
Normální rozdělení - Ing. Jana Fenclová
4ST201 STATISTIKA 2. cvičení 4.8.2013
Slovo úvodem Proměnné a konstanty
Hodnocení testů pro přidělení bodů do systému SCM
UNISTAT
Statistické metody_3.pdf
o neřešené příklady: 12
Příklady a DÚ.
quadro-takk - Euroheat SK
Výběr zaměstnanců IV
Stabilizace létajícího drona v dynamickém prostředí
Základy statistiky
Podrobná kritéria přijímacího řízení na SG
∑ ∑ ∑2
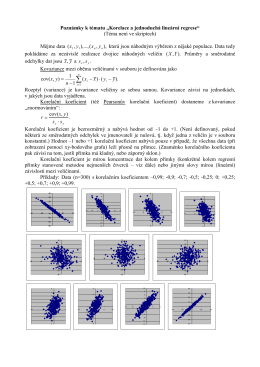
. ), cov( ss yx r ⋅ =
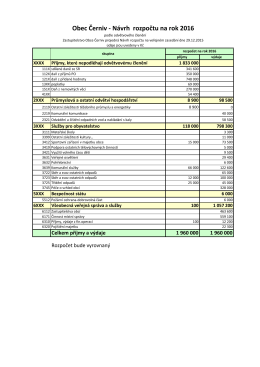
Obec Černiv - Návrh rozpočtu na rok 2016
Anlam Çıkarıcı İstatistik Teknikleri
SKIL ELEKTRIČNI RUČNI ALAT
zde
NEPARAMETRICKÉ METODY
Aplikovaná statistika 2007 program přednášek pro 2. ročník denního