Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
zde
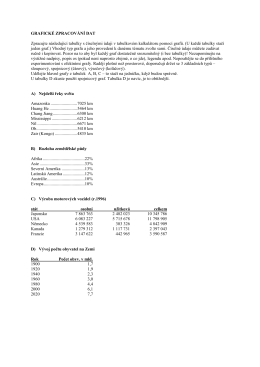
Zpracujte v excelu pomocí grafů
Explorační faktorová analýza - analýza hlavních
Recenzovaný časopis pro otázky společenských věd Auspicia 2014/3
Výroční zpráva 2013 po stranu 24
Studium polymorfismu u vybraných populací
Kapitola 2 - Testování hypotéz. Testy dobré shody
Grafy-význam grafov, použitie grafov v štatistike. Grafické prostriedky
Slovo úvodem Proměnné a konstanty
PSYCHOLOGICKÉ TESTY
Statistické metody_1.pdf
Úvod do studia statistiky
Základy statistiky