Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Statistické metody_1.pdf
Úvod do studia statistiky
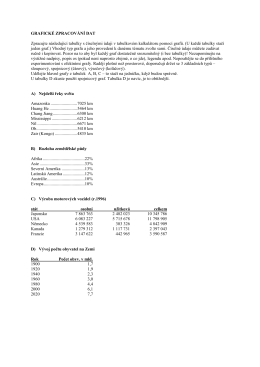
Zpracujte v excelu pomocí grafů
Grafy-význam grafov, použitie grafov v štatistike. Grafické prostriedky
zde
Milost pro Ninive
IBM SPSS Data Preparation
Panoušková - Úprava odborného textu
Plánování projektu
Úvod do geografického vzdělávání Kritické čtení
Zápis VS 18.10.2014
Hunger-games-2-vrazedna
Nabídka na zpracování diplomové práce od People Management Fora
Zpravodaj města Úštěk
Doporučená praxe Řízení rizik - Společnost pro projektové řízení
Všeobecné obchodní podmínky
Zobrazit/otevřít - Publikace UTB Repozitář publikační činnosti UTB
Obchodní podmínky LR Health & Beauty CZ v souboru pdf
MUDr. František Sabol, Ph.D. Chirurgická liečba disekcie aorty typu A
POHÁDKA - vymyšlené vypravování
ZadaniExcel
Slides, graphs, tables, diagrams
ISTAV - INFORMAČNÍ SERVIS VE STAVEBNICTVÍ Statistiky