Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Úvod do studia statistiky
Spravodaj č. 01/2013
Statistické metody_1.pdf
Propozice regionálního poháru žactva 2015/16
SNY A MÝTY
paneurópska vysoká škola fakulta práva vymožiteľnosť práva.
PLANIMETRIE, SHODNOST A PODOBNOST
Profesní ozáření - Státní ústav radiační ochrany
Tlačová správa 14. 07. 2016 Prílet
Samohláska říjen_2010.indd
1 Základní statistické pojmy, charakteristiky souboru
zadání tutoriálu
CVIČENÍ A HRY (NEJEN) K IMPROVIZACI LEKTOR MgA. Mgr
Sférická a Cylindrická perspektiva
Sylabus AKD II. - Analýza kvantitativních dat
Presentace - Jeroným Klimeš
zde
vystava_v_predvecer_valky.pdf
BEMS - Nelumbo Energy as
Nápověda k aplikaci ve formátu PDF ke stažení
Základy statistiky
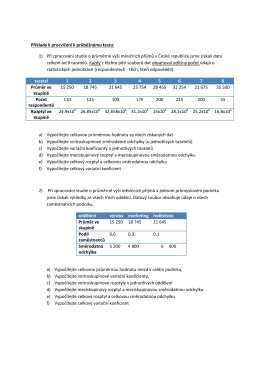
Příklady k procvičení k průběžnému testu: 1) Při zpracování studie o
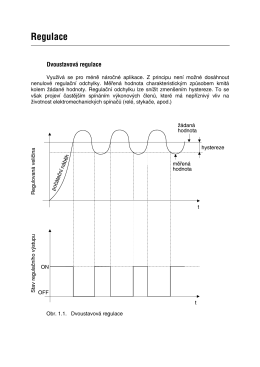
Jednoduchý popis dvoustavové a PID regulace.