Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Základy statistiky
Zmluvné vzťahy
návrh elektrických pohonov pre mecanum kolesový
September - avelmak.sk
karta 3A - Grad Karlovac
Youcat – Sva tost smí ř ení .
ARDUINO – příručka programátora
LÁSKA PENÍZE VRAŽDA
1 Základní statistické pojmy, charakteristiky souboru
Teplý, B.: Jak lze chápat ekonomickou výhodnost u veřejné zakázky?
srpski pdf
Zájezdy
Slovo úvodem Proměnné a konstanty
KAMPANĚ JSOU KREATIVNĚJŠÍ
kontingenční tabulky v excelu aneb jak vytřískat z dat co
SEZNÁMENÍ A PRÁCE S DOKUMENTY NA POČÍTAČI
Explorační faktorová analýza - analýza hlavních
12 Závislost dvou kvantitativních proměnných: regrese
Stabilizace létajícího drona v dynamickém prostředí
4ST201 STATISTIKA 2. cvičení 4.8.2013
Komise: Komise č.01 - GAHOT-HOT1
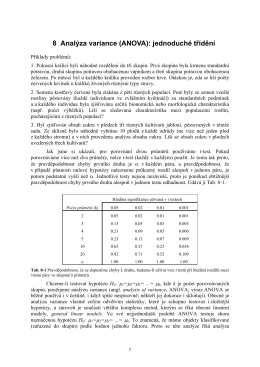
8 Analýza variance (ANOVA): jednoduché třídění
ZP RAVO DA J