Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
NEPARAMETRICKÉ METODY
02 Binární soustava
UNISTAT
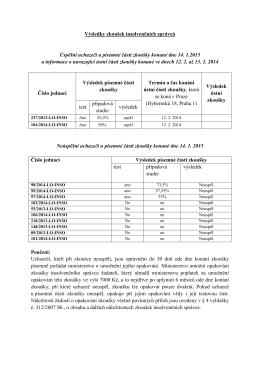
Výsledky zkoušek insolvenčních správců Úspěšní uchazeči u
Řešení
Cvičení ze statistiky
Cvičení ze statistiky
Aplikovaná statistika 2007 program přednášek pro 2. ročník denního
Jozef Chajdiak - STATIS Bratislava
Slovo úvodem Proměnné a konstanty
Evidence Přenosu daňové povinnosti
4ST201 STATISTIKA 2. cvičení 4.8.2013
Úloha 1: Kvalita měření vysokých napětí A) Zhotovení
6. Neparametrické metody
Pribeh a cil hry
RA-Školení
PRAVDĚPODOBNOST A MATEMATICKÁ STATISTIKA
4ST201 – STATISTIKA CVIČENÍ Č. 7
(Metodologie pedagogického výzkumu)
Zobrazit/otevřít - Publikace UTB Repozitář publikační činnosti UTB
7 Neparametrické metody Nonparametric methods ( ) ( )
Opakovani C
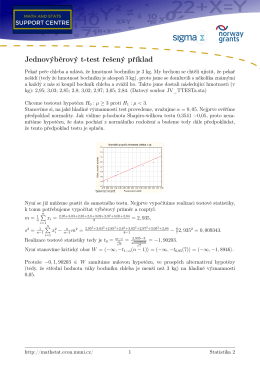
Jednovýběrový t-test řešený příklad