Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
12 Závislost dvou kvantitativních proměnných: regrese
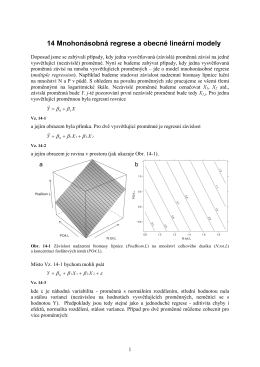
14 Mnohonásobná regrese a obecné lineární modely
Úlohy z fyziky Úlohy jsou čerpány z publikace Tématické prověrky z
Správa pre úvodnú oponentúru úlohy výskumu a vývoja
Převody problémů a NP
Dopasowanie prostej do zbioru punktów doświadczalnych
Zde - OK1GTH
Frekvencní menice
1420 KB - Makina Mühendisleri Odası
Základy statistiky
1 Základní statistické pojmy, charakteristiky souboru
EMC - godina III_broj 2.indd - EMC
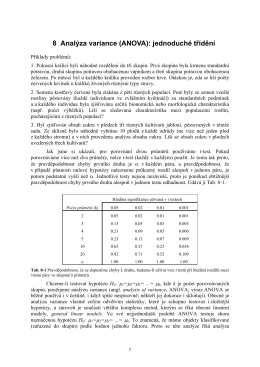
8 Analýza variance (ANOVA): jednoduché třídění
Jak se učit? Odb(p)orné šlamastyky
Chemic k é k o tvy 3 Chemické kotvy
Statistické minimum - Bohumil Minařík.pdf
Záměr přefinancování komunálního dluhopisu ISIN CZ0001500102
o neřešené příklady: 12
/ Prevziat
zkouška Statistika pá 3. 2. 2011, 900, B uč. H1 výsledky a termín
Otázky k ústní zkoušce
null
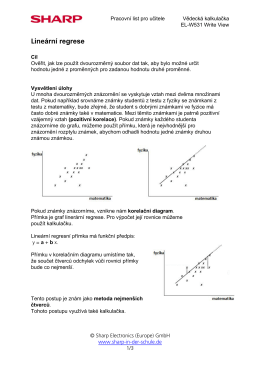
PN2: Statistické výpočty, lineární regrese