Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
8 Analýza variance (ANOVA): jednoduché třídění
10 Transformace dat v analýze variance
Zdravotní náměty
Základy pravdepodobnosti a matematickej štatistiky
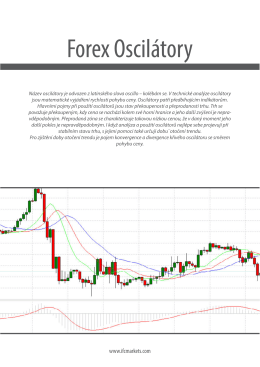
Forex Oscilátory
9 Dvoucestná analýza variance
Metody Analizy Danych Doświadczalnych. Wybrane zagadnienia
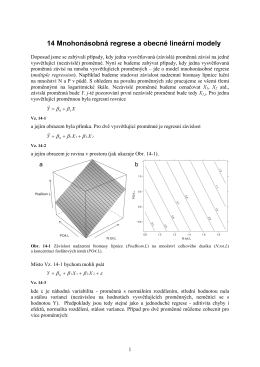
14 Mnohonásobná regrese a obecné lineární modely
dendrologické dni v arboréte mlyňany sav 2012
Vnitřní předpis o finanční kontrole a vnitřním kontrolním systému
Przydatne rzeczy w R
Somatický profil probandů baletního souboru Brna a Olomouce
Tübitak Bilim Fuarları Destekleme Proğramları Duyurusu