Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
ÇUKUROVA ÜNİVERSİTESİ FEN BİLİMLERİ
21. yüzyıl mimarlık ortamı için yapılabilecek eleştirilere - Lab-On
Sınıf Öğretmeni
. \3 ^cR.2-a\\
System instalacyjny Hep O DO INSTALACJI CIEPŁEJ I ZIMNEJ
tutaj - TARCZA
etkili tsunami modellemesinde ağsız radyal bazlı fonksiyon
Holografija u 3D AdS gravitaciji sa torzijom
İşbirlikli Öğrenme Yönteminin Cinsiyete Göre Okuduğunu Anlama
İndirmek İçin Tıklayınız
i. ,n - tulipany.cz
Kalp yetersizliğinin nadir bir nedeni: Lomber disk hernisi ameliyatına
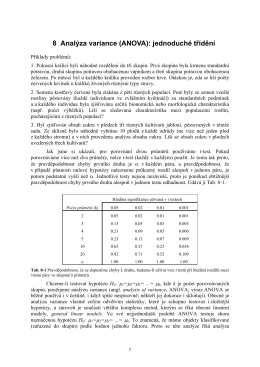
8 Analýza variance (ANOVA): jednoduché třídění
Politikalar, yaklaşımlar ve örnekler : A vrupa bağlamında öğ renim
Ek Dosyayı İndir - Hitit Üniversitesi
Full Text (PDF) - Turkish Archives of Otolaryngology
TG – 5 - İhtiyaç Yayıncılık
temel sayma kuralları
İndir (PDF, 1.5MB)
= - n! P(n,r) n r !
ABB i-bus® KNX Akıllı Tesisat Sistemleri Sistem açıklaması
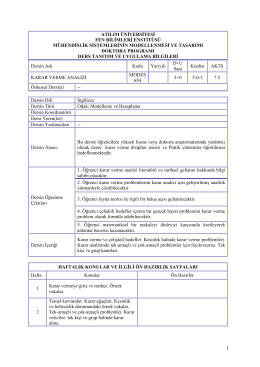
atılım üniversitesi fen bilimleri enstitüsü mühendislik sistemlerinin
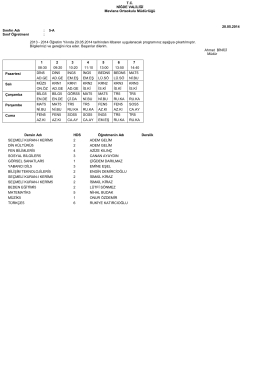
19.12.2014 - Ankara Sanayi Odası