Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Základy pravdepodobnosti a matematickej štatistiky
buradan indirebilirsiniz
Studija zaštite kanjona Cijevne
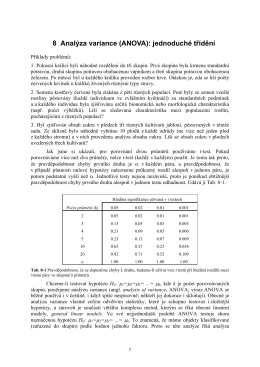
8 Analýza variance (ANOVA): jednoduché třídění
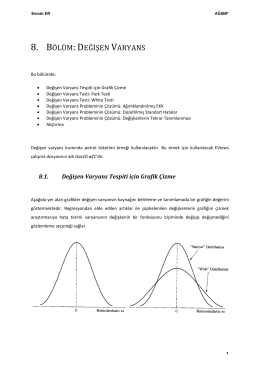
8. BÖLÜM: DEĞİŞEN VARYANS
a>2 - Sakarya Üniversitesi
/ Prevziat
∑ ∑ ∑2
Základní příkazy v R
Wybrane metody statystycznego repróbkowania
Ekonomické ukazovatele v zdraví a zdravotníctve
Redukcja liczności zbiorów z wykorzystaniem systemu R
3 - Université de Caen
aproximácia binomického rozdelenia normálnym a príklad jej
/ Prevziat
BTTOP1314.pdf
Testy o dvou nezávislých náhodných výberech Necht` X11 ...X1n1 je
ผลการรักษาโรคเนื้องอกสมองชนิด germ cell ในเด็ก วิช
Oznámenie o konaní povinného seminára zo Štatistiky pre
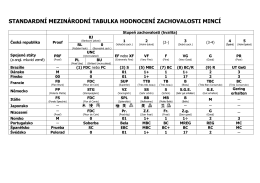
standardní mezinárodní tabulka hodnocení zachovalosti mincí
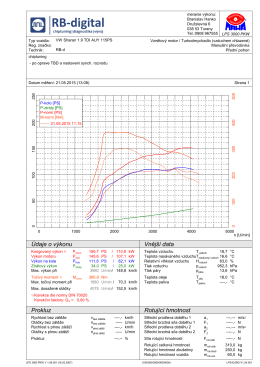
RB-digital.sk | chiptuning VW Sharan 1.9 TDI 115PS
Zápis poznámek setkání Program a vize PS březen
RB-digital.sk | chiptuning Skoda Octavia 1.9 TDI