Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Regresní analýza
SOUČaSNé a PErSPEKTIvNí MOžNOSTI FarMaKOTEraPIE
Skripta (234-261)
Slovo úvodem Proměnné a konstanty
Jazyková proměnná jako strukturní jednotka
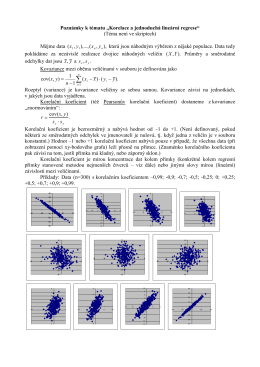
. ), cov( ss yx r ⋅ =
0 - JAK PLAVE JAK?
ANOVA pro 2 faktory
ZDE - Lara Wellness
Metody výzkumu
Frekvenčný menič SED2 Návod na obsluhu
Vyjmenovaná slova M
Matematická statistika II Regresní a korelační analýza
08 - Mocniny a odmocniny
Zkratové proudy I. - ELEKTRO
SAMOSTATNÝ PROJEKT Z EKONOMETRIE – zápočtová práce
Elektrotechnika 2 (BEL2) - pracovní sešit pro přednášky
Kvantitatívne metódy v ekonomike
Aplikovaná statistika 2007 program přednášek pro 2. ročník denního
6.4 Multikolinearita
funkce - Student na prahu 21. století
teoria_logaritmicka_funkcia.pdf
Stanovení nenasycené hydraulické vodivosti pomocí mini