Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Ročník 23, číslo 3, září 2012 - Česká statistická společnost
V E Ř E J N Á V Y H L Á Š K A
Metódy výpočtu konfidenčných intervalov pre referenčnú hodnotu v
IBM SPSS Complex Samples | Acrea
ostravská univerzita v ostravě
číslo 7 - Slovenská štatistická a demografická spoločnosť
W zdrowym ciele zdrowy duch - Przedszkole Przyjaciół Książki
Hodnocení kvality měření šíjového projasnění v prvním
Pokročilejší metody statistické regulace procesu
Otázky
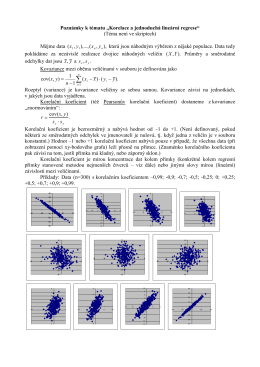
. ), cov( ss yx r ⋅ =
procella - Q-DAS
www.yousigma.com
BERMAD Řízení pracovního tlaku
Teoretické otÃÂ
Troubský hlasatel červen 2013
Korektura 2
Stiahnite si obsah a úvod učebnice v pdf formáte
ZNALECKÝ POSUDEK č. 1069-58/2015 - E
Al-7075 Malzemesinin Freze Tezgâhında Delme İşleminde Farklı
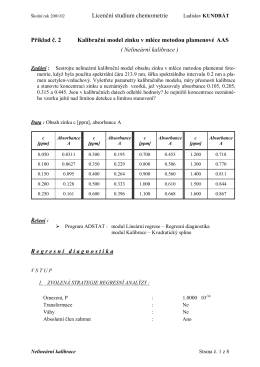
Nelineární kalibrace
Skuteczne metody wychowawcze i terapeutyczne dla dzieci i
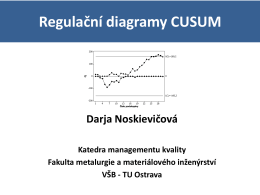
Regulační diagramy CUSUM