Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
VERİ MADENCİLİĞİNDE TEMEL BİLEŞENLER ANALİZİ VE
UKMOP 2015 Timur DOĞU
Basit Seri
Lecture3
Enerji Verimliliği ve Uygulamaları Semineri
6 Midterm แนวข้อสอบ ภาคเรียนที่ 1 ป.6 2557
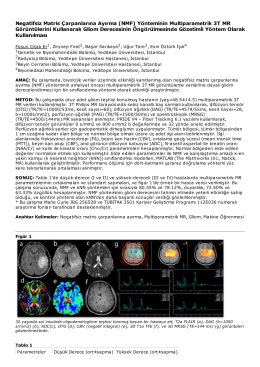
Negatifsiz Matris Çarpanlarına Ayırma (NMF
Ders 9 - Dağıtık Veritabanı ve Oracle RAC - Altan MESUT
Avrupa Ülkelerinin İntihar Oranlarına Göre Sınıflandırılması
možnosti aplikácie zhlukovej analýzy v manažérskych podnikových
Yaygınlık ölçüleri
(dgs \347\375km\375\376 soru k\374nye.indd)
9.Kan - Uzman Veteriner
Ölçme ortamından kaynaklanan hatalar
Genişletilmiş Özet Gönderme (Extended Abstract Submission)
Asal Çarpanlar ve Bölen Sayıları
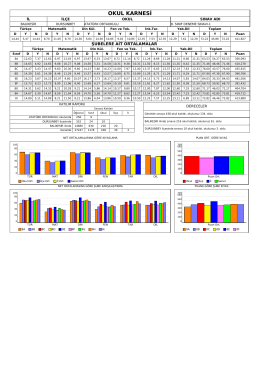
OKUL KARNESİ
ALGORİTMA VE PROGRAMLAMAYA GİRİŞ Prof.Dr.Mustafa ERGÜN
Prezentácia
Algoritma
Sunu1_31.61 MB
Table of Contents A. Original Research
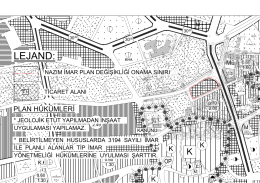
Bey mah. ticaret alanı nazım imar plan değişikliği Öneri