Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
Bulletin v pdf - Česká statistická společnost
Lineární algebra - Marie Hojdarová.pdf
"Idősorok I. " c. tárgyhoz - 6. rész (.pdf file, letölthető)
Kvantitativne metode.pdf - Seminarski i diplomski radovi
Otevřený dopis adresovaný českému Ministerstvu zahraničních věcí
číslo 7 - Slovenská štatistická a demografická spoločnosť
Profesora Zygmunta Zahorskiego „wykład” o pochodnych
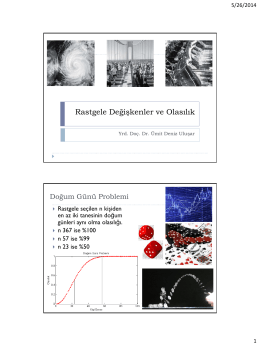
Rastgele Değişkenler ve Olasılık
leden - HEXXA komunikační agentura
PRAGMATISMUS A PRAGMATICKÁ PEDAGOGIKA
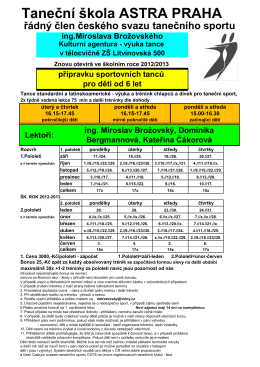
Taneční škola ASTRA PRAHA
Modül Bilgi Sayfaları
HATAY GUIDE