Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
číslo 7 - Slovenská štatistická a demografická spoločnosť
oz_bredova_kovacova.pdf
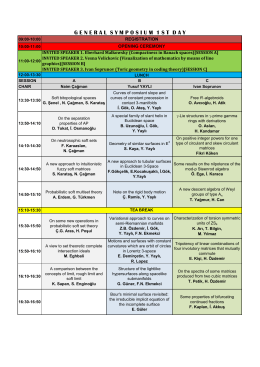
generalsymposıum 1 stday
Vzhledem k tomu, že 1. ledna 2012 začalo tříleté funkční období
Ročník 25, číslo 3, září 2014 - Česká statistická společnost
null
Bulletin v pdf - Česká statistická společnost
Používanie mozgu v biodromálnom meradle a v
ISSN 1336-7420 - Slovenská štatistická a demografická spoločnosť
číslo 7 - Slovenská štatistická a demografická spoločnosť
/ Prevziat
Risk Measures in Non-life Insurance Company Miery rizika v
číslo 7 - Slovenská štatistická a demografická spoločnosť
Nezamestnanosť a vybrané aspekty demografického správania
The distribution function as a tool for judging the extent of risk
PROGRAM KONFERENCIE - nitrianske štatistické dni
Stretnutie štatistických spoločností v Bratislave
Marec 2014 - Slovenské národné múzeum v Martine
A Competing Risks Model for the Time to First Goal