Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
SZZ - Zpracování a rozpoznávání obrazu.pdf
ZPRACOVÁNÍ DIGITALIZOVANÉHO OBRAZU
Akce Mitutoyo - WHP Technik, s.r.o.
JBG 201, 202, JCDT 10 přehrávač podkr. hudby
Státní závěrečná zkouška - Ekonomická fakulta Jihočeské univerzity
Patobiomechanika srdečněcévního systému
Lineární algebra - Marie Hojdarová.pdf
Když vaše aplikace potřebuje vidět
skripta 2 - cev viana
Bulletin v pdf - Česká statistická společnost
Patobiomechanika srdečněcévního systému
Namety ETV - Etická výchova
Rekonexe magnetického pole, current-sheet, X-bod
A2M31SMU - SIGNÁLY V MULTIMÉDIÍCH SEZNAM OTÁZEK VE
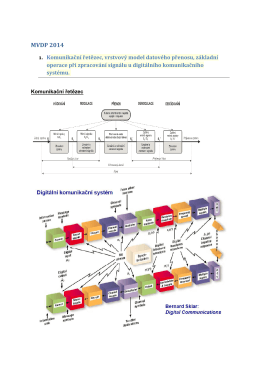
MVDP 2014 v1.pdf
Turbulence
regulované soustavy_PID
Metody rozpoznání objektů v obrazu.pdf
25. Fourierovy řady. Diskrétní Fourierova transformace, její použití a
analiza czasowo-częstotliwościowa sygnałów niestacjonarnych
Studijní text [pdf] - Vysoká škola báňská
více zde - Bytové družstvo Machkova 8/1645
FLIR T1020 - FLIRmedia.com


















![Studijní text [pdf] - Vysoká škola báňská](http://s2.readgur.com/store/data/000160718_1-d95a5a9380a165cde53a83e470e059b8-260x520.png)

