Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
doğrusal regresyon modeline matris yaklaşımı
8-1 8. DEĞİŞEN VARYANS SORUNU (HETEROSCEDASTICITY
EM205 – Çalışma Soruları 25.12.2014 NOT: “... bir fonksiyon yazınız
Genel Ürün Broşürümüzü İndirmek İçin Tıklayınız
pptx
MATLAB ile Meslek Matematiği Kullanım Kılavuzu
11. Kovaryans ve Korelasyon
Dengeleme Hesabı 1
Ch 10+11
Dengeleme Hesabı 1
3.sınıf _deneme sınavlarımız
Çözüm - EBA
Digitalni sistemi - Vanr.prof.dr. Lejla Banjanović
çoklu doğrusallık sorunu
1.2 Dizisel Uzaylarda Süreklilik
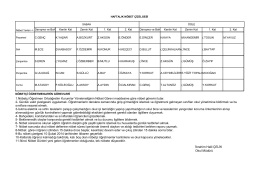
İbrahim Halil ÇELİK Okul Müdürü 1.Nöbetçi Öğretmen Ortaöğretim
Sunu41.59 MB
Štatút školy - Cirkevná základná škola svätého Pavla NOVÁ DEDINA
27-30 mart 2015 iddaa oyun programı
BENZETİM
Uzunluk Ölçüleri, Ayşegül Tunç
Regresní model s fixními a náhodnými efekty (s príklady)
Regresní model s fixními a náhodnými efekty (s príklady)