Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Identifikacije
14.2. Širokopojasni PLC sistemi kao rešenje za prenos
Program Broşürü - Bilkent Senfoni Orkestrası
Linearni statistički modeli – Skripta
Identifikácia LTI systémov
7. DRUGI PRINCIP TERMODINAMIKE ZA ZATVORENE
Naučni časopis "Financing" - Broj 3 Godina 2 / septembar 2011.
IZVEŠTAJ O TRANSPARENTNOSTI „KLS REVIZIJA“ D.O.O.
1. Vektorski prostori
PDF dokument - ATLAS
C2 00 - CIGRE Srbija
File - Početna
4.10.2012 1 Računari Sadržaj predmeta Sadržaj predmeta Sadržaj
ANALIZA OTPADNIH VODA, IZVEŠTAVANJE I
Karakteristike
Horalová Kalinová Michaela, Horal Stanislav
curver 1.0 - Jakub Kinšt
II DEO DINAMIKA PROCESA I DRUGIH ELEMENATA SISTEMA
(Microsoft PowerPoint - BOKS-D\216ENKINSOVA STRATEGIJA
1. Meta Mehmed - Socioeconomica
null
otkrivanje grubih grešaka
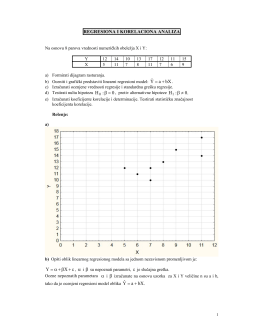
REGRESIONA I KORELACIONA ANALIZA bX aYˆ + = 0