Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
otkrivanje grubih grešaka
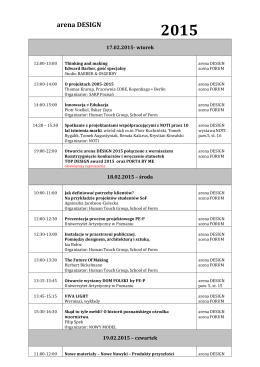
arena DESIGN
Univerzálny informovaný súhlas
Pročitajte cijelu studiju
TÜRK PSİKOLOGLAR DERNEĞİ Genel Merkez Yönetim Kuruluna
DUPONTTM TYPAR® SF GEOTEKSTIL
(Microsoft PowerPoint - BOKS-D\216ENKINSOVA STRATEGIJA
Драган Ђорђевиђ - Брка: Археолошка истраживања Пусте Реке
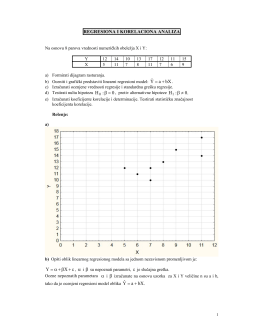
REGRESIONA I KORELACIONA ANALIZA bX aYˆ + = 0
Nefro 29.pdf - Savez bubrežnih invalida Vojvodine
Identifikacije
null
S5750E-SI Series L2 Gigabits Dual Stack Intelligent
1.1 8 Port Yönetilebilir Switch 1.1.1 Cihaz üzerinde en az 8 port 10
พฤติกรรมอันถูกต้องที่เที่ยงธรรม การให
D - Ústav telekomunikácií