Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Power point örnek uygulaması
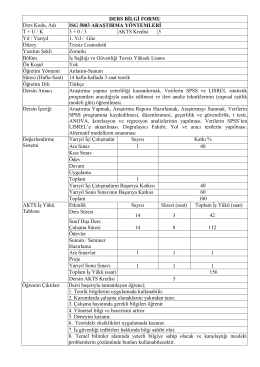
DERS BİLGİ FORMU
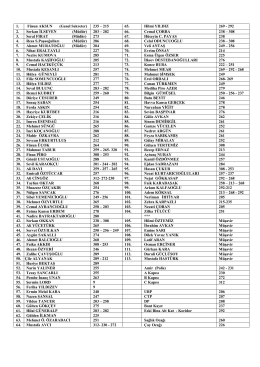
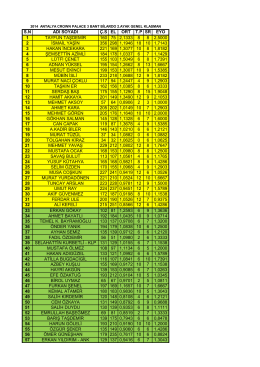
1. Füsun AKSUN (Genel Sekreter) 235 – 215 65. Hilmi YILDIZ 269
Document
Anlambilimsel sınıflandırılmanın iMRG görüntülerinde
Anlambilimsel sınıflandırılmanın iMRG
bu linkten - İzmir Büyükşehir Belediyesi
İstatistik Temel Kavramlarına Giriş
Soru 3. z=x Soru 6. Soru 7. 4x Soru 9. Soru 10.
Öz Abstract Giriş Euro Bölgesinde İşsizlik Histerezisinin İkinci Nesil
ÖĞRETİM YÖNTEM VE TEKNİKLERİ
Klemsan Trunkie Pano içi Kablo Kanalları
çoklu doğrusallık sorunu
NetMaster 1 Port Ethernet+1 Port USB ADSL2/2+
Lecture3
ZAMAN SERİLERİ EKONOMETRİSİ I : DURAĞANLIK, BİRİM
S.N ADI SOYADI Ç.S EL ORT T.P SR EYO 1 TAYFUN TAŞDEMİR
Wybór formy funkcyjnej modelu
Zyxel P660-T1 V3 POTS üzerinden 802.11g Kablosuz
Complex Analysis
Yeniden Düzenlemiş Simpleks
istatistik ıı uygulama : hipotez testleri
HACETTEPE ÜNİVERSİTESİ