Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
İstatistikî İfadeyle... / Statistically Speaking
Sözel Bildiriler
TÜRKÇE, BİLİM VE FELSEFE ÜZERİNE
Kadınlarda anorgazmi KADIN CİNSEL SAĞLIĞI
2014 Yılının En Büyük Salgını: Ebola Virüs Hastalığı
DİREN ÇAKMAK ESERLERİNE YAPILAN
T.C. SAĞLIK BAKANLIĞI TÜRKİYE HALK SAĞLIĞI KURUMU
peak eco enerji
SPSS ile Korelasyon ve Regresyon Analizi
Giresun Orman İşletme Müdürlüğü.pdf
Ders3-Tanımlayıcı İstatistikler
EFQM 2013 Model Tanıtımı - Stratejik Planlama ve EFQM Şube
Yaygınlık ölçüleri
alıştırmalar
View/Open
sayi 10 sayfalar.indd - Samsun Dişhekimleri Odası
Grup Ahlak ve Davranış Kuralları
Almanca Öğretmen Adaylarının Teknopedagojik Eğitime Yönelik
Document
Tam Metin - SED - Sanat Eğitimi Dergisi
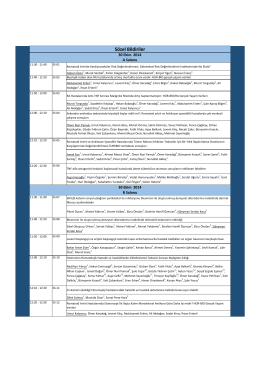
GÜN 09:00-09:30 Tanışma 09:30-09:35 Günün Programı 09:35
38 Yabancı Turistlerin Müşteki “Mağdur” Olarak Müdahil Oldukları
verze v pdf - Analýza kvantitativních dat