Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Interpret jazyka IFJ2011
Platební příkaz
záměr obce č. 5 2016
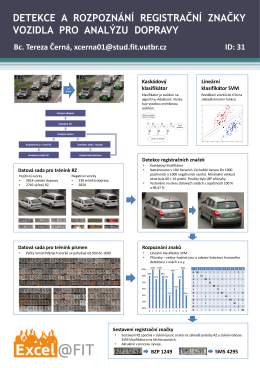
detekce a rozpoznání registrační značky vozidla pro
odkaz
(Microsoft PowerPoint - Blue-light LED [Re\236im kompatibility])
Programovanie v jazyku JAVA Cykly Mgr. Lukáš Zmuda
Detekce a rozpoznání registracní znacky vozidla - Brno
Číslicové obvody a jazyk VHDL
Logika a formální sémantika
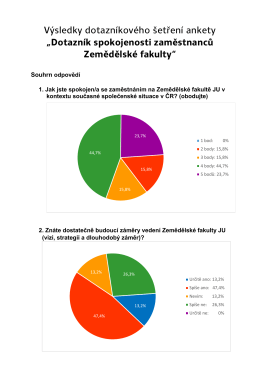
Dotaznik pro zamestnance Zemedelske fakulty
Przykładowa konfiguracja Asteriska
Doporučení strategie
přednáıka 3
Základní algoritmy pro počítání s celými a racionálními čísly
DISTRIBUCE
Základy programování a algoritmizace
Liveryman HARMONY 2246
RTL Biathlon Manual CZ.pdf
Nástěnná/stolní ČASOMÍRA 90090
Manuál - Biometrie
iZ_06_2013 - Portál městského obvodu Plzeň 2
Základy PHP



![(Microsoft PowerPoint - Blue-light LED [Re\236im kompatibility])](http://s1.readgur.com/store/data/000730289_1-6661d840cb91f4d901caeb563ed2572d-260x520.png)