Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Yazılım Hata Kestirimi İçin Veri Analizi - CEUR
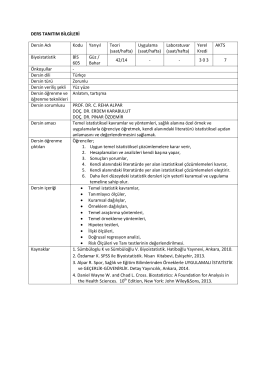
BİS 605 BİYOİSTATİSTİK
KPZ`2013 - Konferencja Projektów Zespołowych
Sermaye Şirketlerinin Tasfiyesinde Şirket
Bulletin - Laboratórna medicína
ISTQB Advance Level Test Analyst jegyzet
ovde - Slobodan softver u školama
OPATRENIE Ministerstva financií Slovenskej republiky z 24
výkaz mirko účtovnej jednotky
Trendy a budúcnosť odporúčania online správ
účtovná závierka
Genel Bakış - World Bank
Aktuální leták KIKA - Nákupní park
Hafta 10
sağlıkta adres - Başkent Üniversitesi Ankara Hastanesi
Kuruluş Adı Kuruluş Adresi Kuruluş Telefonu Kuruluş Fax
ODAS I Sheraton Otol i.
Poređenje metoda ocenjivanja parametara na podacima iz
ORGANIZACJA BIURA
dört teker kontrollü direksiyon sisteminde bulunan
dijital medya
1185 - มหาวิทยาลัยเทคโนโลยีราชมงคลอีสาน
Autonomous Weapon Systems, the Frame Problem, and Computer