Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Hibrid Algoritma ve Isıl İşlem Algoritmasıyla Test - CEUR
ROZWIĄZANIA I PROIEKTOWANE STANDARDY
DNA REPLİKASYONU
Pazarlama Araştırmalarında Deneysel Yaklaşımlar
öğretmen adaylarının çoklu zeka algıları
STAR - Ak Parti
Upute za montažu i održavanje Spremnik za pripremu
Arzu ÇEBİ Huriye ÇİFCİ
Akut gut atağı tedavisi - Geleneksel 13. FTR Uludağ Sempozyumu
Makaleyi Yazdır
Kullanıcı Arayüzü Tasarımlarının Üst Düzey - CEUR
B-Spline Curve Approximation using Pareto
univerzita komenského v bratislave pedagogická fakulta dienesov
ULL- TEK PANO
Geçmişe Dönük Hata Tespit Oranlarının Zamanla - CEUR
falco, kronospan
2015-2019 Stratejik Planı - Kastamonu İl Özel İdaresi
Untitled - 4. tüketici hukuku kongresi
roboski müzesi ve anma yeri mimari tasarım yarışması ilk grup
Herkese aynı kalite, kişiye özel proje
BROMĠNATÖR
Beklentiler ve Yaşam Tercihlerine Göre Şekillenen
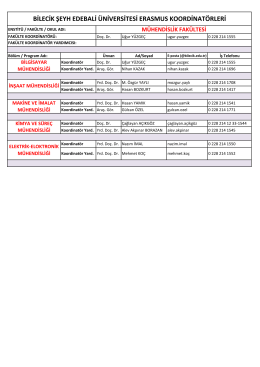
Mühendislik