Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Geçmişe Dönük Hata Tespit Oranlarının Zamanla - CEUR
Akut gut atağı tedavisi - Geleneksel 13. FTR Uludağ Sempozyumu
Statik ve Dinamik Analizler ile Hesaplanan Risklere - CEUR
Sıkça Sorulan Sorular - TEV İnanç Türkeş Özel Lisesi
Envanter Yönetimi
Wojciech Dominik Porównanie właściwości chmury punktów
Hibrid Algoritma ve Isıl İşlem Algoritmasıyla Test - CEUR
Microsoft SQL Sever
i̇çi̇ndeki̇ler önsöz
Motive çalışanlar olmadan zorlu hedefleri başarmak imkansız
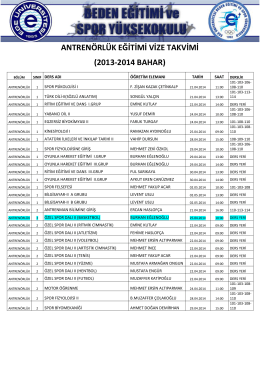
1. Öğretim - Beden Eğitimi ve Spor Yüksekokulu
Slayt 1
Sunum İçin Tıklayınız
Verimli Ders Çalişma Yöntemleri - İSTANBUL - ÜMRANİYE
2 I. GENEL KURUL SEÇİM SONUÇLARI ve KURULLARIN OLUŞUMU
Sakarya İline Ait Yangın Verilerinin Veri Madenciliği Yöntemleri İle
IIBA Uluslararası İş Analizi Teknikleri Eğitimi 2 Gün - BA
PDF súbor - Ústredný archív SAV
2015 Q3 - Borusan Mannesmann
02_Jenkins_Milenkovi..
Karaciğer Nakli Yapılan Hasta ve Hasta Yakınlarının
PhDr. Soňa Kovačevičová DrSc. - inventár
ulusal pıyano yarışması - Hacettepe Üniversitesi