Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
Bulletin v pdf - Česká statistická společnost
Identifikace a návrh °ízení pro model kuli£ka na plo²e
Buletin 2013 - Stredná odborná škola POLYTECHNICKÁ
možnosti aplikácie zhlukovej analýzy v manažérskych podnikových
Perspektívy výučby cudzích jazykov pre 21. storočie
Zoznam publikačnej činnosti
ZNALOSTI 2012
Manuál ke zpracování závěrečných prací
Öğrenci Performansının Veri Madenciliği İle Belirlenmesi
Plzeň 1994, Učitel výtvarné výchovy – umělec a pedagog
Multi-Word Units in Imaginative and Informative Domains
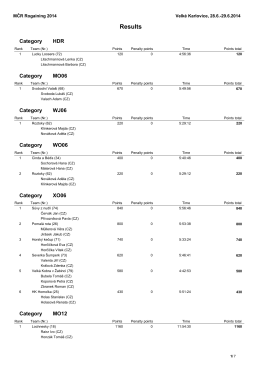
Results
Forex Akşam Bülteni