Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Multi-Word Units in Imaginative and Informative Domains
UNITEX à l`Université de Belgrade
Bilgisayar Oyun Dergileri ve Yabancı Dil Olarak
GOLDEN GRAMMAR RULES BY MICHAEL SWAN
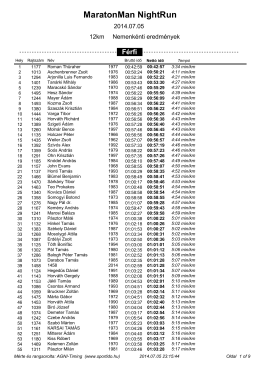
12 KM
BEYOND IDENTITY: - Stanford University
Bulletin v pdf - Česká statistická společnost
Proceedings of LFG10 - Stanford University
Handout - Homepages at cavar.me
Sample presentation slides (Blue bar design)
Zdeněk Beránek – Alžírsko. Krize devadesátých let
Çok İşlevlilik Açısından Türkçe Edatların Söz
THE WORLD IS OUR PLAYGROUND
A Hungarian NP Chunker Gábor Recski and Dániel Varga
System automatycznej konwersji mowy polskiej na
Untitled
トルコ共和国 (Republic of Turkey)
Savoury Crepes (minimum 350 g) Vegetarian Crepes
I. ve IV. yarıyıllar (2013-2014 yıllarında kayıtlılar)
CV - Department of Foreign Language Education
Mise au point d`une méthode d`annotation morphosyntaxique
CV in Turkish - Department of Foreign Language Education
Standard of Living Factors with Respect to Environment in Selected