Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Multiprocesorski sistemi Uvod Podešavanje okruženja Zadaci
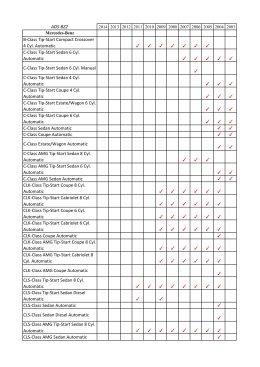
ADS-BZ2 B-Class Tip-Start Compact Crossover 4 Cyl. Automatic C
Amerikada Akademik İnceleme ve Araştırma NOVA
WYK6
ovde
TP 1 Expressions rationnelles - LRDE
uputstvo - AutoTrack.rs
bu linkten
MPS - Uputstvo - Multiprocesorski sistemi
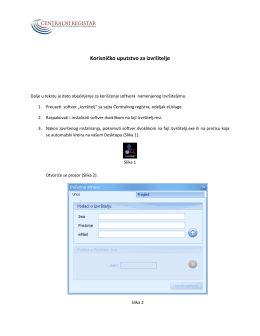
Korisničko uputstvo za izvršitelje
Drugi domaći zadatak iz OOP, 2011/2012
7. Reoloji - Dokuz Eylül Üniversitesi
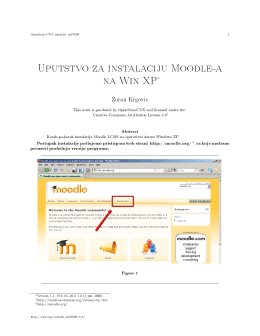
Uputstvo za instalaciju Moodle
Makale PDF - Güncel Gastroenteroloji
Digitalna elektronika II 20140331.pdf
1. Uvod u korišćenje Linux operativnog sistema
Uputstvo za skidanje drajvera
Sortiranje.
Uputstvo - E-Smart Systems
Portal Kreditinog biroa
ovde - Laboratorija za Statistiku
Full Text - Journal Of Business Research
Početak