Read
Gur
☰
Explore Categories
Sign in
Sign up
Upload
×
Download
No category
OKTAY, Melek-KURT, Atakan-KARA, Mehmet-TÜRKÇE İÇİN
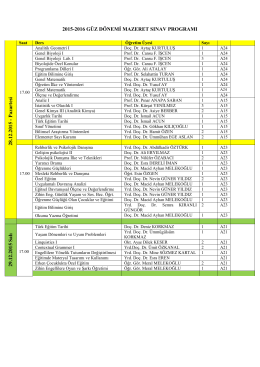
2015-2016 Güz Dönemi Mazeret Sınav Programı
karşıtlıklar temelinde atatürk söylemi incelemesi
8-10. SINIF “TÜRKÇE VE TÜRK KÜLTÜRÜ”DERS
2012_ulusal_biyoloji_A_kitapcik
Documents To Go-Kullanıcı Kılavuzu
PowerPoint Sunusu
Doç. Dr. Cihan KARAKUZU - Bilecik Şeyh Edebali Üniversitesi
GARANTİ MİNİ BANK 11. ÇOCUK FİLMLERİ FESTİVALİ 2014
Siyanür Yönetilebilir
EROL, İ . Lütfü-HELVACI, Zeynep-KÜLTÜREL KIMLIKTE
Türkmen Türkçesi ile Türkiye Türkçesinin Sentaks Bakımından
AUTOCAD 2014 2D kreslení