Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Öğrenir Derlemleri: Kapsam, Tasarım ve Uygulamalar
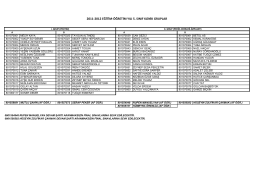
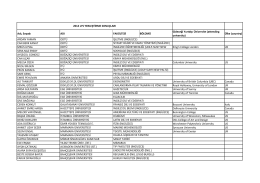
2011-2012 eğitim-öğretim yılı 5. sınıf klinik gruplar
Web Tabanlı Türkçe Ulusal Derlemi (TUD)*
TEKST JEDNOLITY STATUTU SPÓŁKI FLUID SPÓŁKA
Bilten br.150 - Resursni centar civilnog društva
Ülke (country)
Septembar - Omladinska mreza BiH
Procedurální model jazyka - Katedra obecné lingvistiky
Doing Diversity in Education June 6-7, 2014 Istanbul Policy
Les Masters
Katalog 2 - OPALINOX
Đstatiksel Bilgisayarlı Çeviride Paralel Derlemin Büyüklüğünün ve
oğuzhan karakaş - Boston College
BILTEN - WordPress.com
Stolní PC Athlon XP 1700+ cena s DPH
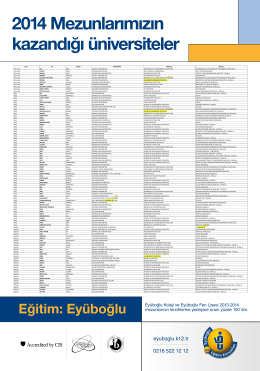
Eyüboğlu Koleji ve Eyüboğlu Fen Lisesi 2013
PLAN LOTÓW W SEZONIE 2014 ODDZIAŁ 013 EŁK Harmonogram
TCPDF using CakePHP - Hacettepe Üniversitesi Çağdaş Türk
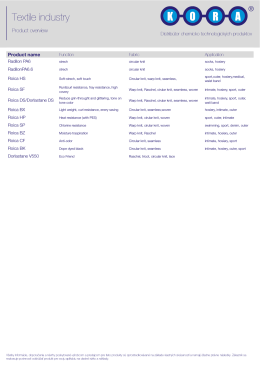
Textile industry