Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Web Tabanlı Türkçe Ulusal Derlemi (TUD)*
Hacettepe Sözlük Bilimi Uygulama ve Araştırma Merkezi tarafından
Sample presentation slides (Blue bar design)
Tarihsel Gelişim İçinde Üniter Bir Yapıda Yerel Yönetim - E
Datenblatt FUJITSU Workstation CELSIUS C620
türk sözlükçülüğünün bugünü ve geleceği
Öğrenir Derlemleri: Kapsam, Tasarım ve Uygulamalar
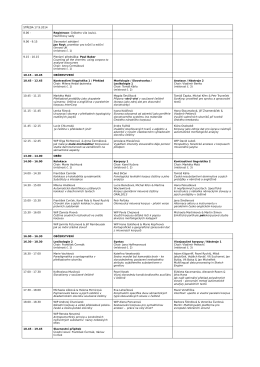
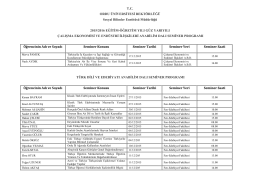
předběžná verze programu
Kutsal - Mersin Üniversitesi
Knihu abstraktů - Český národní korpus
articles - Slovenský národný korpus
haber metinlerinin kategorizasyonunda varlık isimleri ve konu
Ek 11.1: Ekosistem Hizmetleri Kontrol Listesi
Problematika vývoje herně-výukové aplikace pro předškolní děti
Ulotka PDF
T.C. ORDU ÜNİVERSİTESİ REKTÖRLÜĞÜ Sosyal Bilimler Enstitüsü
Mikrobiyoloji bülteni 26 Eylül 2015
Bu PDF dosyasını indir
Đstatiksel Bilgisayarlı Çeviride Paralel Derlemin Büyüklüğünün ve
Deyimlerde BiIdirtnin D~zenleniş Biçimi ve Ozellikleri
currıculum vıtae - Selçuk İşsever
541.35 KB - Inet-tr
Türkçe Tümcelerin Sonunu Belirlemede Açık Kaynak / Ücretsiz