Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
IEEE Conference Paper Template
POLITYKA COOKIES Niniejsza Polityka Cookies określa
7 Şubat 2014 Mersin Üniversitesi - Akademik Bilişim Konferansları
Untitled
En Yakın k Komşuluk Algoritmasında Örneklere Bağlı Dinamik k
ETNİSİTE ve MİLLİYETÇİLİK - Ankara Üniversitesi Dergiler Veritabanı
İletişimde Farkındalık
TÜRK HAVA KURUMU ÜNİVERSİTESİ BİLİŞİM
tc selçuk üniversitesi fen bilimleri enstitüsü hotamış gölü çevresinin
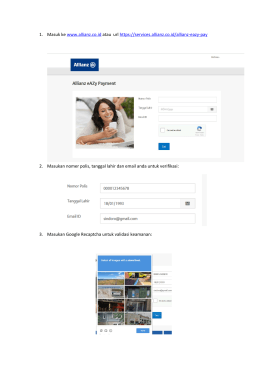
Panduan Allianz eAZy Payment
istanbul satış yerleri
Stratejik Plan ( 2015 – 2019 ) - Niğde Sosyal Bilimler Meslek
6 rektör ve 68 dekan atanacak
Uzman Kararlarının Yeni Bir Geçiş Fonksiyonuyla Birleştirmesi
nazar boncuğu sağlık sigortası
moral destek hastalık sigortası
Bölüm-9-sunu
Pobierz Politykę Prywatności w PDF.
ankara üniversitesi fen bilimleri enstitüsü yüksek lisans tezi parçalı
Celé znění vzkazu v češtině - fanzine KELLYWORLD 06/2014
fanzine KELLYWORLD 10/2014
36 kV ORTA GERİLİM METAL MAHFAZALI VE LSC 2B/2A
ผลของแบบอักษร การหมุนเอียง และชุดอักขระ ต่ออ