Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
sborník IT - cssi
“ประเทศไทย” เป็นเจ้าภาพหลัก ส่งเสริมสินค้าม
Technická příručka instalace a zálohování
Opis teczek
16.03.2015 Bankacılar Dergisi
Egzamin ITIL Foundation
Nr 36/2014 - Goral info
Robot Karel sa učí jazyk C Programovací jazyk
Integrácia BCM do interných procesov
Windows Storage Server 2012 R2 çalıştıran Dell Depolama Ağa
competitiveness of czech ict heis graduates - cssi
ICT Consulting – Bezpečnost informací a dat
PDF Download - Türkiye Aile Hekimliği Dergisi
inspirace - Veletrh řešení
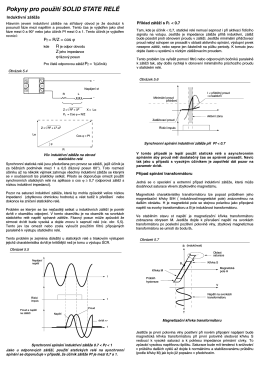
Pokyny pro použití SOLID STATE RELÉ
Zdeněk Kvapil
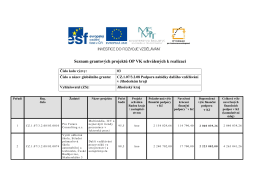
Seznam schválených GP v oblasti podpory 3.2
Pozvánka na konferenci
Zeszyt numer 22 - Studenckie Koło Naukowe Prawników
program konference - Fond Otakara Motejla
random-091227023041-phpapp02 - ดาวน์โหลด