Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Základy statistiky 4
více
Motto: Mnoho jinychsportu klade na ty, kteri je chteji
zde
Počet lidí bez práce se v lednu meziměsíčně zvýšil, meziročně jejich
zde
Nezaměstnaných bylo v dubnu nejméně od ledna 2009
Základní příkazy v R
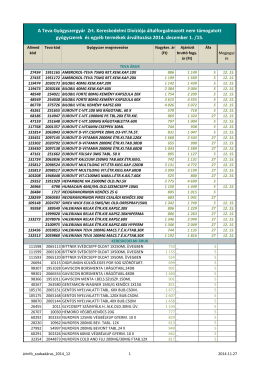
A Teva Gyógyszergyár Zrt. Kereskedelmi Divíziója
Języki i metody programowania. Ćwiczenie 8. Tablice liczb i znaków
` VESTNIK No 19, May 13, 1949* SEZKAM SPERKU A JINICH VECI
Matematická statistika II Regresní a korelační analýza
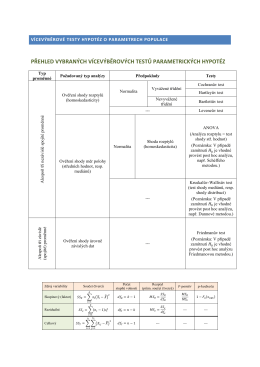
přehled vybraných vícevýběrových testů parametrických
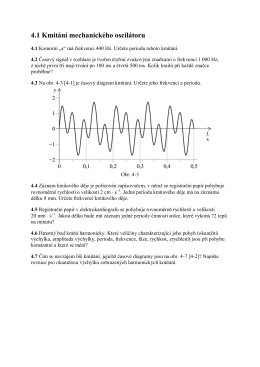
4.1 Kmitání mechanického oscilátoru
VI- PTTBANK HİZMETLERİ ÜCRETLERİ
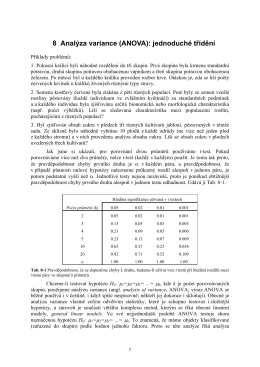
8 Analýza variance (ANOVA): jednoduché třídění
Krajská hygienická stanice Zlínského kraje
219 ğudur. Bu sebeple gerek tarihsel süreçte gerekse Yahudiliğin
PRAVDĚPODOBNOST A MATEMATICKÁ STATISTIKA
ccods 5142 wh
Katalog produktů ke stažení ZDE
Metodika výkonnostních zkoušek
ZAMAN SERİLERİ EKONOMETRİSİ I : DURAĞANLIK, BİRİM