Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
null
REKLAMACE
hodnocení - AT-CZ
Upřesnění informace k odhadovanému počtu a distribuci žáků se
NP2 právo trestní
Metodika rozpoctov 4_3_1.pdf
ZDE - Sokrates
P-Okultní krvácení
Opracowanie eksperymentu
úvod, teória a vzorce
4ST201 – STATISTIKA CVIČENÍ Č. 7
Hodnocení kvality měření šíjového projasnění v prvním
Pro-SALE! SÍLA TRADIČNÍCH A DYNAMIKA
i. ,n - tulipany.cz
Attenuation Measurements of Overvoltages on Contact Line
Dodatek k učebnici IFRS praktické aplikace
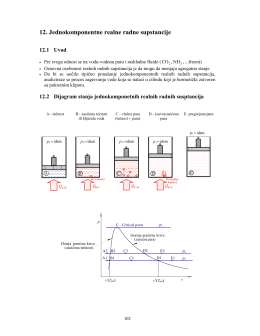
Dijagram stanja
Otto Dvořák Možnosti statistického posouzení kvantitativních
Statistické minimum - Bohumil Minařík.pdf
Diskurzní ironie v českém jazykovém prostředí
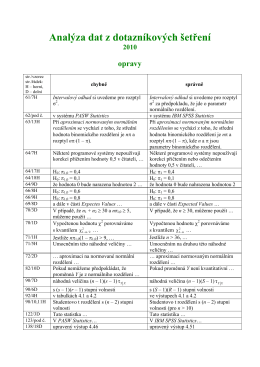
opravy
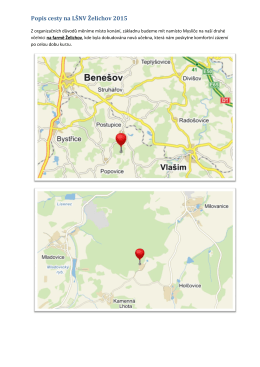
Popis cesty na LŠNV Želichov 2015
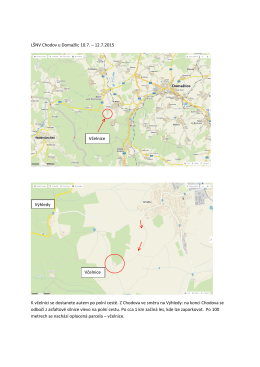
LŠNV Chodov u Domažlic 10.7. – 12.7.2015 K včelnici se dostanete