Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
i. ,n - tulipany.cz
REKLAMACE
Podrobný popis funkcí
Овдје
OVID Kolay Kullanım Rehberi
Araştırma Soruları-2
AE2014 Sonuç Bildirgesi
ÇUKUROVA ÜNİVERSİTESİ FEN BİLİMLERİ
Tematické celky Nové informatiky
овдjе.
4ST201 – STATISTIKA CVIČENÍ Č. 7
the document in pdf format
Zobrazit/otevřít - Publikace UTB Repozitář publikační činnosti UTB
Informace o využití protokolu SIA DC-09 - T
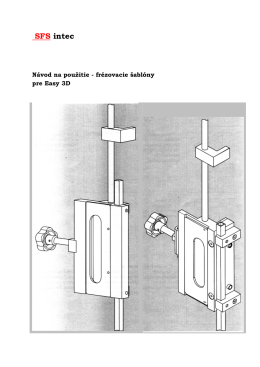
Easy 3D - šablony
VÝVOJ INCIDENCE POZDNÍCH KOMPLIKACÍ U
PACHNĄCA WIOSNA - Nasz Elementarz
null
Daně a daňová problematika_2.pdf
Algoritmus Apriori
PROPOZÍCIE - Základná umelecká škola Sabinov
1. Centrální limitní věta 2. Chyba 1. a 2. druhu 3. Charakteristická
Numerické metody a programování Lekce 7