Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Třídicí algoritmy a násobení matic
Leták o svozu odpadu
Třídění
Technologie filtace vody
PROGRAMOVANIE V LAZARUSE PRE MATURANTOV
Vyhledávání a třídění
Algoritmy a datové struktury I finální verze 2011 (opravy možné
Leták o třídění odpadu
nova verzia
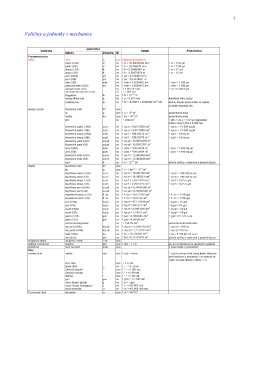
Sbírka úloh z mechaniky (autorem je doc. Habrman)
produktové portfolio elektronických nástrojů pro správu
CAP 710 - Kathrein
WEB Araştırma Yöntemleri
HACETTEPE ÜNİVERSİTESİ
n - Bilkent University
Elementární funkce a základní elementární funkce
file: öğrenci toplantısı
lect08
Domaci pekarna Moulinex
- ZUŠ JN Filcíka, Chrast
Document
Manažment akútneho infarktu myokardu (STEMI) na Slovensku
skladovy program 2012_1_corporate-2014