Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
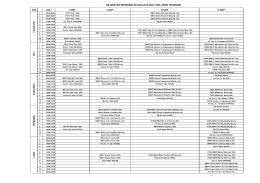
BM307_W2
Raport z badań diagnostycznych dotyczących rozwoju
Dr$i$LEni naxaNl,rcr
Mitochondrial serine protease HTRA2 p.G399S
HematoLog - Türk Hematoloji Derneği
Mart-Haziran 2015 dönemi Konferans Programı hk
Couchbase 2.0
Oturum Başkanı: TacoDibbits(RijksMuseum)
Uluslararası Adli Bilişim Sempozyumu
file: öğrenci toplantısı
Obj. č.: 138 04 94 Obj. č.: 138 04 95
Sürdürülebilir Arazi Yönetimi İş Forumu
Manuel utilisateur
FOTOSORTER - aky technology
CZ-Amalgamy Kerr k.v..pdf
Minimizacija logickih funkcija
Manuel utilisateur
Infortrend Řada diskových polí ESDS
Doç. Dr. Metin KESLER - Bilecik Şeyh Edebali Üniversitesi