Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Spatial Modeling of Climate
Telepítsd magad kertöntöződ
VESTEL OTEL ÇÖZÜMLERİ
KTR - Ürün Kesiti (Türkçe)
Bałtyk
8/2015 - Obec Kuchařovice
Tematski Dosije br. 2 - Pilane
•Guyana Büyükeçiliğinin Türkiye temsilciliği
Open Access PDF - Preslia - The Journal of the Czech Botanical
journal 3/2010 - Lafarge Cement a.s.
emin ellerde - Sondakika Gazetesi
Nosislav 2012 pdf - Výstava vín Velké Němčice
Katalog-2013 - Mendelův vinařský spolek Šardice
SZ T5-1
Alternativní zdroje energie
Samsun İli Örneği - Ege Üniversitesi
Cenník - Commander.sk
Field-Map katalog [PDF 3.9 MB]
A Portable Setup for Fast Material Appearance Acquisition
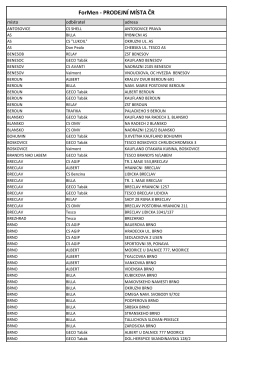
ForMen - PRODEJNÍ MÍSTA ČR
Formulaire d`inscription 2017 – (évaluation en - City
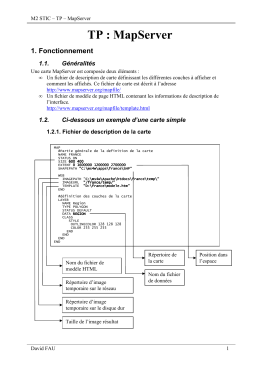
M2 STIC TP MapServer
















![Field-Map katalog [PDF 3.9 MB]](http://s2.readgur.com/store/data/000167134_1-6c3e61fcc58741540c4958f5c19409a7-260x520.png)