Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Knihu abstraktů - Český národní korpus
předběžná verze programu
Tłumacz przysięgły a pułapki tekstów medycznych
Zde - Oddělení gramatiky
zde - Katedra obecné lingvistiky - Univerzita Palackého v Olomouci
J A Z Y K O V Ě D N É A K T U A L I T Y
Web Tabanlı Türkçe Ulusal Derlemi (TUD)*
Přednáška doc. RNDr. Vladimíra Petkeviče, CSc.
Diskurzní ironie v českém jazykovém prostředí
Segmentace textu na věty
Mluvnice soucasné ceštiny
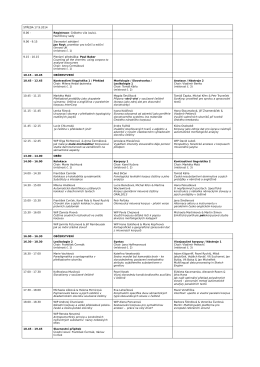
Program
Kontaktové jazykové jevy, bohemismy, v současné slovenštině 1
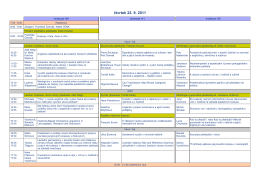
čtvrtek 22. 9. 2011 - Český národní korpus
SemanWc Role Labeling (의미역 결정)
Cvrček, V. 2015. On Some Methodological Issues of CADS
View/Open
Vliv negace na délku jednotek různých jazykových rovin v mluvené
introduction - Univerzita Karlova
Natural Language Processing, Corpus Linguistics, E
full text pdf
Shoda doplňku v reflexivních konstrukcích v češtině*