Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Složitost algoritmů
Časová a paměťová složitost
Wstep do informatyki - Architektura i działanie komputera
Návod - Barbone
zde - Teorie vědy
1. Fourierova transformace
River - GEOS AGT sro
Programowanie niskopoziomowe
Střelectví - Myslivost
Moderní metody řízení nákladů (Ukázka)
4 ความรู้เบื้องต้นเกี่ยวกับการเขียนโปรแกรม
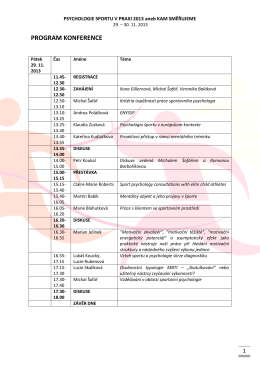
Psychologie sportu 2013
Architektura počítačů Úvod Architektura počítačů Úvod
Stiahnuť
nová kariéra pro zkušené místo pro mě
Programowanie niskopoziomowe
Kódování instrukcí
Časová zložitosť
Relace
Vzorová Přijímací zkouška FIT ČVUT (Mgr.)