Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Dosyayı İndir
LOHRA TYPOVÝ PLÁN
this PDF file
Tamara Naumović Primena statističkih metoda u medicini
DERSHANECILER “EĞITIM DEVAM EDIYOR
Diş hekimliği araştırmalarında mikrobilgisayarlı
EET 103 Algoritma ve Programlama Ders Notu
Rękawice robocze
Yurtdışı Öğretmen Görevlendirme Kılavuzu
Wyniki-2012 - Alpin Sport
GRUP TOPLU İŞ SÖZLEŞMESİ AMAÇ Taraflar işçi - Birleşik Metal-İş
2) matlab dosya kontrol yapıları 1
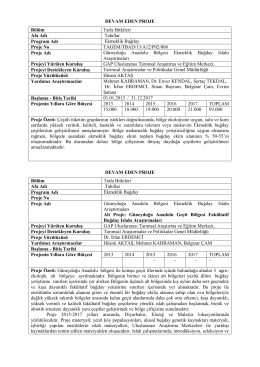
DEVAM EDEN PROJE Bölüm Tarla Bitkileri Afa Adı Tahıllar Program
Korelasyon Analizi - anadolu üniversitesi eczacılık fakültesi
Hledáme nové obchodní příležitosti Looking for new
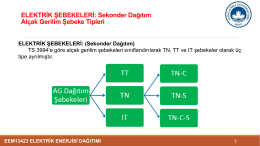
Engineering Sciences Status : Original Study ISSN: 1308 7231
III.Sunu - Personel Web Sistemi
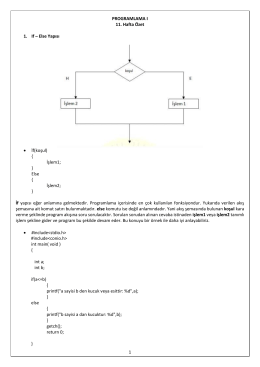
1 PROGRAMLAMA I 11. Hafta Özet 1. If – Else Yapısı • İf(koşul
ESNEK ÇELİK DİKMELER / TEKNİK ÖZELLİKLER
Slayt 1 - Gebze Ticaret Odası
Serhat Teker Portfolio
25-31 Ağustos 2014 Haftası Denizcilik Haberleri