Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Metin Sınıflandırma Text Classification
Full-coverage Identification of English Light Verb Constructions
product placement as a marketing communication tool
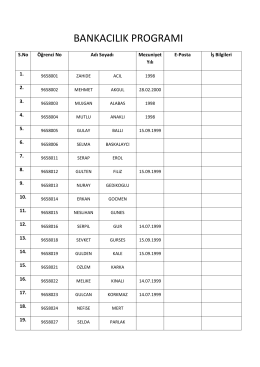
Bankacılık Bölümü Mezunları
Çözüm - Yarbis
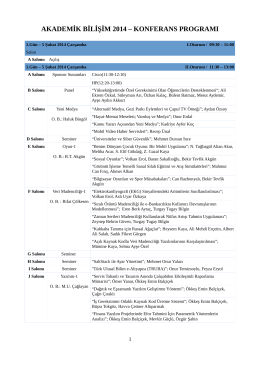
akademik bilişim 2014 - Akademik Bilişim Konferansları
Ezgi Yıldırım
Evening
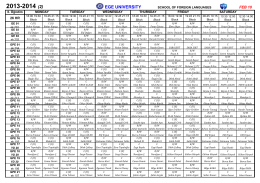
Nesne Tabanlı Programlama Ders Hakkında Ders
web tabanlı akıllı bir durak sisteminin gerçeklenmesi
VENEZIA
INTELIGENTNI SISTEMI Sadržaj izlaganja
Türkçe ve Doğal Dil İşleme Turkish Natural Language
KÜÇÜK ADIMLAR Erken Özel Eğitim Programı Küçük adımlar 0
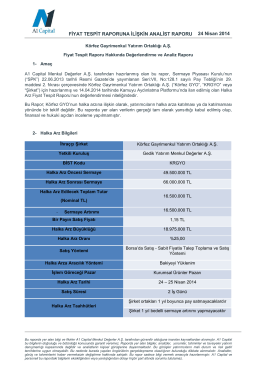
Körfez GYO - A1 Capital
Text Categorization-11
Đstatiksel Bilgisayarlı Çeviride Paralel Derlemin Büyüklüğünün ve
baskı 4.baskı
Kalite İyileştirmede Veri Madenciliği Kullanımı ve
16, Sayı: 1, Yıl: 2014, Sayfa: 159-178 ISSN
özerden plastik sanayi ve ticaret a.ş.
Sunu21.49 MB
ecoMill ve ecoMill V