Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
INTELIGENTNI SISTEMI Sadržaj izlaganja
SISTEMI REALNOG VREMENA Operativni sistem realnog vremena
PU 2 Metode grupisanja - Vanr.prof.dr. Lejla Banjanović
Samoodrživa kuća po postulatima Tesline doktrine
ESTRIH I VLAGA - ISUŠIVANJE ILI ZATVARANJE?
Knn, Nn, Bayes, Dt Ve Svm Kullanılarak Ekg Vurularının
Klasifikacija aero snimaka - Laboratorija za digitalnu obradu signala
Babor Beauty Journal 09
DIREKTNE STRANE INVESTICIJE I CRNOGORSKA PRIVREDA
The Effects of Using Student-Generated and Expert
Metin Sınıflandırma Text Classification
Text Categorization-11
Preuzmite broj 14.
inteligentni sistemi - Vanr.prof.dr. Lejla Banjanović
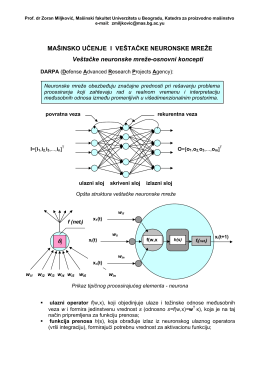
Машинско учење и вештачке неуронске мреже
SRV 3 Ugradeni racunarski sistemi - Vanr.prof.dr. Lejla Banjanović
Propagačný leták katedry - katedra mineralógie a petrológie
Perceptron
КАРДИОВАСКУЛАРНЕ БОЛЕСТИ
E® SUBTITLE Samočisticí sklo Popis SGG BIOCLEAN
inteligentni sistemi inteligentni sistemi
KONVEKSNO PROGRAMIRANJE 1
konveksna analiza 1