Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
Rad
CUDA Advance - nvidiakoreapsc.com
CUDA i OpenCL
ความรู้เบื้องต้นของโครงสร้างข้อมูลและขั้นตอนวิธี
CUDA basic - nvidiakoreapsc.com
Wykład 4 - Politechnika Warszawska
Kurs maklerski Maklers.pl
BIST 30 Spot ve Futures Piyasalarında Güniçi Fiyat Keşfi ve
Grafik˙Islemcileri Üzerinde Paralel Parçacık Süzgeci Kullanarak
Excelde Finansal Uygulamalar
mart / ožujak - Federalni hidrometeorološki zavod BiH
april / travanj - Federalni hidrometeorološki zavod BiH
pdf - GIS Day Serbia
Prezentacja z ćwiczeń - Programowanie Współbieżne 2015/2016
ความรู้เบื้องต้นของโครงสร้างข้อมูลและขั้นตอนวิธี
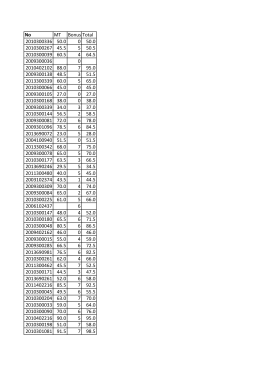
No MT Bonus Total 2010300336 50.0 0 50.0 2010300267 45.5 5