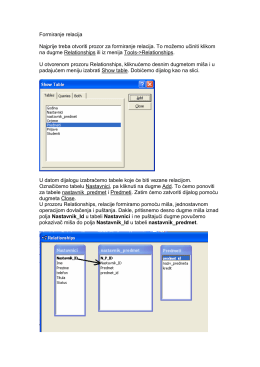
Read
Gur
☰
Explore
Log in
Create new account
Upload
×
Download
No category
BAZE PODATAKA
BAZE PODATAKA - WordPress.com
Sažeci referata 2014.pdf
ระบบสืบค้นรูปภาพบนอินเตอร์เน็ตโดยใช้หลักกา T
Ufuk 2020 Marie Skłodowska-Curie Araştırma Programları ve
Formiranje relacija u Accessu
Informacioni sistem za korisnike Zaštitnog fonda Federacije BiH
บทที่ 5 Relational Algebra Relation Calculus
YBP106 Veri Tabanı Ders1
UVOD U GEOGRAFSKE INFORMACIONE SISTEME
Programski jezik C - cas1
kliknite ovde - ITS-a
Programiranje 1
gis sistemi
OSNOVNI POJMOVI BAZE PODATAKA
Baza podataka je uređeni skup međusobno po
TDV DIA - İslam Ansiklopedisi
Скуп као основни математички појам
VTYS - Hf5 - Normallestirme
2014-1 Veri Tabanı Yönetimi Dersi Laboratuvarı 1. Quizi (Grup 1-3-4
Systemy baz danych
Uputstvo programa.pdf
PROGRAMOVÁNÍ V SQL